KAISTのハン・ドンス教授の研究チーム、数百万ウォンのゲーム用GPUでAI 学習…速度 104倍向上
支配的だった「不可能」論を打破…AI競争、最終的には「価格競争」へ
中国のAI(人工知能)スタートアップであるDeepSeek(ディープシーク)が、低コストのAI半導体を使って学習した「高性能・低コストAI」を公開した。しかし、韓国ではすでに昨年、DeepSeekが使用したH800よりも安価な「ゲーム用GPU」でAI学習を行った事例があり、今、注目を集めている。また、DeepSeekのAI開発コストを下げる核心技術「MoE(Mixture of Expert・混合専門家モデル)」も韓国で実装された。
DeepSeekが公開したR1が話題になったのは、NVIDIAの格落ちGPU(グラフィック処理装置)H800を使用したからだ。1基6,000万ウォン(約640万円)ほどする高性能GPUのH100を用いたChatGPTとは異なり、H100に比べて性能は30%劣るものの、価格は数千万円安いH800を活用して、高性能AIの開発に成功した。一方、KAISTの電気・電子工学部ハン・ドンス教授の研究チームが昨年9月に公開した分散学習フレームワーク「Stella Train(ステラトレイン)」は、H800よりも安価な100 万〜300 万ウォン(約10~30万円)の低価格GPU を活用している。韓国のネットカフェでも使用されているNVIDIAのゲーム用GPU「RTX」だ。「フレームワーク」とは、AI制作に必要なツールを集めた一種の「AI生成の枠組み」である。
研究チームはRTX 10基とCPU(中央処理装置)を並列接続し、学習速度を向上させた。また、高速ネットワークがなくても学習できるように、ネットワークの速度に合わせてデータを圧縮・送信するアルゴリズムを適用した。その結果、同じRTXを使用するMeta(メタ)のAIフレームワーク「PyTorch(パイトーチ)」よりも学習性能が104倍向上した。PyTorchは、世界中で最も多く使用されているオープン型のAIフレームワークである。RTXの約2倍の性能を持つH100と比較すると、安価なGPUで性能を52倍まで向上させたことになる。従来、このレベルの性能を出すには、数億ウォン規模のH100複数台と、それらを接続するための毎秒400Gbps(ギガビット)級の高速ネットワークが必要だった。
また、研究チームはDeepSeekの核心技術「MoE」モデルを学習できるフレームワーク「ES-MoE」も開発した。「Mixture of Expert・混合専門家モデル」という意味のMoEは、特定の作業に特化した複数のLLM(大規模言語モデル)を集約し、作業の種類に応じて必要なLLMだけを活性化する技術である。メモリ使用量を大幅に減らしながら作業速度も向上させることができる。
ハン教授の研究は、DeepSeekショックが発生する前だったため、当時大きく注目されなかった。ハン教授は、「OpenAIなどの先進的なビッグテック企業が高価なGPUを使用するのには、それなりの理由があると考えられており、低価格GPUを活用する技術はほとんど実現不可能だと見なされていた。」と述べた。
また、「OpenAIがLLM(大規模言語モデル)の規模を大きくするほどAIの精度が向上することを確認し、その結果、世界中のビッグテックがLLMの規模拡大に注力するようになった。高性能GPUをより多く塔載することが『トレンド』になったのはそのため。しかし、AI市場もスマートフォン市場のように、結局は『どの企業がより優れた半導体を使うか』ではなく、『どの企業がより安価なAIを供給できるか』の競争になるだろう。」と説明した。さらに、「低価格GPUを使用したDeepSeekの登場こそがその流れを示すシグナルだ。」と付け加えた。
韓国版のDeepSeek AIを開発したハン教授の研究チームは、今後も誰もが活用できる「低コストAI」の研究を続ける計画だ。大学などの研究機関にとって、数億ウォン規模のGPUを研究用に調達することは難しいからだ。ハン教授は、「リソースの限られた研究者でもAIを活用できるように、インフラを構築することが目標だ。」と述べた。研究結果は、誰でも利用できるようにオープンソースプラットフォームの「Github(ギットハブ)」に公開されている。

KAISTの電気・電子工学部ハン・ドンス教授/写真=KAIST
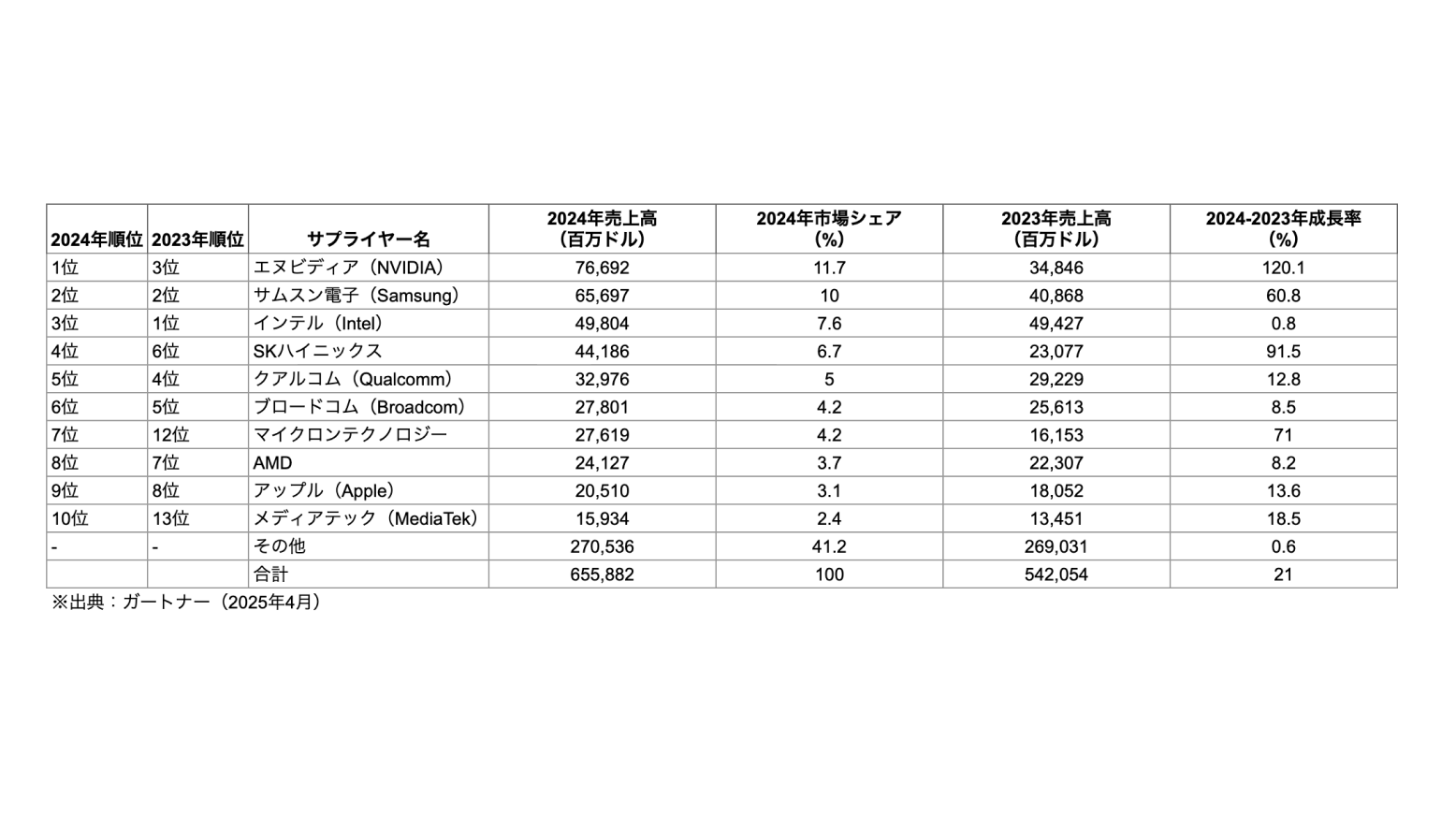
<画像=各社がAI学習に使用したGPUの比較表/イ・ジヘ>
原文:https://www.unicornfactory.co.kr/article/2025013116254787647